
New Delhi. Monday, 15 June 2026
As artificial intelligence cements its role as the defining technology of the 21st century, global superpowers are racing to deploy systems aligned with their respective economic, cultural, and strategic goals. While Western models are largely optimized for English-language dominance, India is charting a entirely different path.
Home to over 1.4 billion people, 22 constitutionally recognized official languages, and hundreds of regional dialects, the South Asian nation is creating a sovereign multilingual AI framework India can use to democratize technology. Driven by state-backed digital public infrastructure, academic research, and a burgeoning domestic startup ecosystem, this model is rapidly becoming a blueprint for inclusive technology worldwide.
Why Western Large Language Models Fail in India
Traditional foundation models frequently encounter structural limitations when deployed in culturally diverse and linguistically rich landscapes. Standard web-crawled training datasets are overwhelmingly skewed toward Latin-script languages. As a result, global AI tools often struggle with the following:
-
High Token Fragmentation: Non-Latin scripts (like Devanagari, Tamil, or Telugu) require significantly more tokens per word in standard tokenizers, making API calls disproportionately slower and more expensive for Indic languages.
-
Code-Mixed Conversations: Millions of citizens routinely blend languages in everyday speech (e.g., Hinglish, Tamlish). Western systems miss the syntactical context of split-sentence language hopping.
-
Lack of Dialectical Nuance: Standard translation tools often overlook rural dialects, which heavily compromises voice-assisted applications in critical sectors like agriculture and public health.
To build true technological self-reliance, the Indian ecosystem is rolling out indigenous foundation models—such as Ola’s Krutrim, the academic initiative BharatGen, and the Indus LLM—designed from scratch with custom tokenizers to address these exact computational and structural gaps.
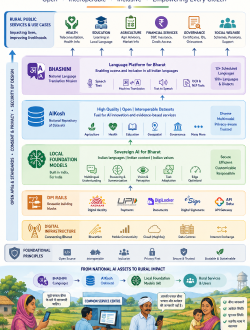
The Strategic Pillars of India’s Language AI Ecosystem
India’s strategy treats linguistic diversity as a primary architectural feature rather than a secondary translation layer. The system is built upon two major, highly integrated components:
1. BHASHINI: The Linguistic Infrastructure Layer
Developed under the Ministry of Electronics and Information Technology (MeitY), BHASHINI serves as an open-access, public digital infrastructure. Instead of isolating language solutions within proprietary walls, BHASHINI provides centralized APIs for text-to-speech, machine translation, and speech recognition across Indian languages. It serves as a unified system where developers, government agencies, and startups can pull standardized translation models into their own applications.
2. The IndiaAI Mission
Backed by a robust government budgetary allocation of over ₹10,371 crore, the IndiaAI Mission targets structural bottlenecks through distinct computing and data storage pillars. The mission is actively expanding national graphics processing unit (GPU) clusters to lower computing costs for startups, while a specialized repository known as AIKosh collects high-quality datasets spanning multiple local sectors.
Cross-Sector Transformations: Agriculture, Healthcare, and Education
By leaning into voice-first and localized systems, India’s multilingual AI framework is actively dismantling the literacy and cognitive barriers that traditionally locked rural citizens out of digital services.
-
Empowering Smallholder Farmers: Agricultural platforms layer voice bots over localized backend systems. Farmers can speak into a smartphone in their local dialect to receive real-time, context-specific advice on pest management, market pricing, and weather anomalies.
-
Decentralizing Rural Healthcare: Multi-language diagnostic chatbots serve as automated triage layers. Rural patients can state their medical symptoms naturally; the AI accurately translates these descriptions into clinical text formats for doctors on remote telemedicine networks.
-
Localizing Technical Education: Educational models are bridging the structural reliance on English-language learning. AI tutors trained on regional technical syllabi allow students to grasp advanced scientific and engineering principles in their native tongue.
Structural Hurdles and the Path Forward
Building one of the world’s most inclusive digital ecosystems is an ongoing journey with unique engineering obstacles. Chief among them is data scarcity. Many regional scripts lack deep, high-quality digitized corpora—a problem often referred to as “low-resource languages.”
The government and research institutions are mitigating this through crowdsourced voice collection drives and synthetic data generation. Additionally, localized training initiatives are underway to address the domestic deficit of deep learning engineers specialized in complex Indic computational linguistics.
Ultimately, India’s language-first approach offers a crucial blueprint for developing nations across Asia, Africa, and Latin America. It demonstrates that true digital sovereignty lies not in adopting imported, monolithic systems, but in building open, equitable, and highly contextualized technology that honors the native tongue of every citizen.
Relevant References and Verification
To follow updates on regional media coverage, community initiatives, and socioeconomic analyses surrounding India’s expanding digital footprint, check the localized reporting published at Matribhumi Samachar English.

